- Published on
字节流 & 比特流
- Authors

- Name
- 皓月之明
Table of Contents
在前后端的数据交换中,常见的格式有 XML、JSON、GraphQL 和 Protocol Buffers 等,现如今可能更常见到 JSON 格式。大部分情况下 JSON 都是很适用的数据格式,但有些特殊场景,可能希望追求更高的编解码效率和更快的传输速度,放弃那种低效的基于 UTF-8 字符串的编解码,例如低延时游戏场景,又或者是大数据量的 IM 消息,更好的方案是使用内存布局更为紧凑的数据流。
在计算机科学中,流是一种特殊的数据结构,有序地封装了一组数据元素。对于一个 Object:
- 将 Object 输出到缓冲区的流称为输出流
- 将缓冲区的数据输入到 Object 的流称为输入流
- 以及同时支持输入和输出的双向流
许多编程语言对流都有对应的实现,例如 C++ 的 iostream 定义标准输入输出流,fstream 定义了文件流,sstream 定义字符流。由于基础数据类型中最小的整型类型是 8 位整数,也就是一个字节,所以实现能用于网络传输的流,最直接的自然是字节流。
后面的文章会介绍两种流的实现。字节流以及内存排列比字节流更紧凑的比特流。
本文的示例代码使用 Rust 编写,尽量使用简单的语法和特性。代码仓库位于 https://github.com/hyzmm/memory_stream
字节流
一个基于二进制缓冲区的数据交换格式,通常会采用单字节类型的数组保存数据,通过记录头部偏移按序写入缓冲区,实现内存字节流。一个输出字节流的结构体只有两个成员变量 —— 字节数组和数据头的位置:
struct OutputByteStream {
buf: Vec<u8>,
head: usize,
}
假设我们要按序写入 8 位布尔值 true,32 位整型值 6E8 ,8 位整型值 127。这个时候缓冲区的内存布局如图所示:

初始头部指针位置为 0。
- 将布尔值
true转换成整型值 1,写入该字节,指针右移 1 个字节 - 将
6E8转换为 4 个字节,分别写入缓冲区,指针右移 4 个字节 - 将 127 写入缓冲区,指针右移 1 个字节
此时,缓冲区实际使用 6 个字节,数据头的位置就是缓冲区数据的长度。
读写任意数据
字节流最基本的方法就是对任意多字节数据的读写支持,在此基础上封装其他数据类型的读写接口就会简单得多。
Rust 代码实现:
fn write<T>(&mut self, data: &T) {
let buf = &mut self.buf;
let num_bytes = mem::size_of::<T>();
// 省略代码:缓冲区剩余空间不足时扩容
unsafe {
copy_nonoverlapping(
data as *const _ as *const u8,
self.buf[self.head..].as_mut_ptr(),
num_bytes,
);
}
self.head += num_bytes;
}
write 方法能够接受任意类型的数据(T)传入,因为只需要知道它的内存地址,不关心它的数据类型。读取的内存长度和写入缓冲区的长度通过 std::mem::size_of 获取类型自身占用的内存大小。将 Object 写入字节缓冲区的方式就是直接把该 Object 的指针指向的内存地址往后 n 个字节复制到缓冲区(memcpy)指针后对应的 n 个字节中。最后缓冲区的头部指针也往后移动数据大小的长度。
下面是对应的读取数据接口:
fn read<T>(&mut self) -> T {
let num_bytes = size_of::<T>();
let bytes = &self.buf[self.head..self.head + num_bytes];
self.head += num_bytes;
unsafe {
std::ptr::read(bytes.as_ptr() as *const _)
}
}
read 方法能够从缓冲区当前位置往后读取一段数据,长度为泛型 T 所占用空间大小,return 时类型推导会自动将它转换为泛型中指定的类型。和写入一样,读取后需要移动头部指针。最后将指针类型转换为对应的数据类型,类似 C++ 中的 reinterpret_cast。
:::warning write 和 read 接口的访问控制没有设置为 public,因为它能够写入任意类型,包括一个自定义结构体。如果控制好环境变量,这没有问题,但是如果不同语言、不同平台或者是不同编译器,可能都会因为它们之间内存布局或字节序上的差异,导致读与写的字节无法对应。 :::
读写基本数据类型
有了 write 和 read 接口,其他读写任意类型的数据会直接调用这两个接口,这也使得其他 API 非常简单。
写入 API
由于 write 接受泛型,写入基本数据类型的接口统一调用 write 写入内存中的数据到缓冲区。
pub fn write_u8(&mut self, data: u8) { self.write(&data) }
pub fn write_i8(&mut self, data: i8) { self.write(&data) }
pub fn write_bool(&mut self, data: bool) { self.write(&data) }
// ... 省略一些接口
pub fn write_f32(&mut self, data: f32) { self.write(&data) }
读取 API
读取基本数据类型的接口统一调用 read 从缓冲区读取数据,读取的长度是泛型类型的大小,类型推导会自动将数据类型转换为对应的返回类型。
pub fn read_u8(&mut self) -> u8 { self.read() }
pub fn read_i8(&mut self) -> i8 { self.read() }
pub fn read_bool(&mut self) -> bool {
let byte = self.read_u8();
if byte == 0 { false } else { true }
}
// ... 省略一些接口
pub fn read_f32(&mut self) -> f32 { self.read() }
读写容器类数据
读写数组和字符串类型的数据不能够直接写入内存数据,至少不能仅仅将内存复制过去,那会导致读取缓冲区时不知道应该读取多少个字节,所以写入容器类型的数据需要先写入长度。
例如,写入字符串的接口定义为:
pub fn write_string(&mut self, data: &String) {
self.write_u32(data.len() as u32);
let bytes = data.as_bytes();
for byte in bytes {
self.write_u8(*byte);
}
}
先写入容器长度,再依次写入所有字节。读取的时候先读取容器长度,再依次读取所有字节:
pub fn read_string(&mut self) -> String {
let len = self.read_u32() as usize;
let mut bytes = vec![0; len];
for i in 0..len {
bytes[i] = self.read_u8();
}
unsafe { String::from_utf8_unchecked(bytes) }
}
使用示例
下面的例子展示了如何使用 OutputByteStream 和 InputByteStream 读写各种数据类型。
#[test]
fn write_read_all() {
let mut o = OutputByteStream::default();
o.write_bool(true);
o.write_i8(127);
o.write_i16(30000);
o.write_i32(65536);
o.write_i64(-5611626018427388000);
o.write_f32(123.456);
o.write_string(&"hello world!".to_string());
let mut i = InputByteStream::new(o.buffer());
assert_eq!(true, i.read_bool());
assert_eq!(127, i.read_i8());
assert_eq!(30000, i.read_i16());
assert_eq!(65536, i.read_i32());
assert_eq!(-5611626018427388000, i.read_i64());
assert_eq!(123.456, i.read_f32());
assert_eq!("hello world!", i.read_string().as_str());
}
字节序
本节关于字节序的描述主要来源于维基百科:字节序。
字节顺序,又称端序或尾序(Endianness),在计算机科学领域中,指内存中或在数字通信链路中,组成多字节的字的字节的排列顺序。
在网络应用中,字节序是一个必须被考虑的因素,因为不同机器类型可能采用不同标准的字节序,所以均按照网络标准转化。大部分处理器以相同的顺序处理位(bit),因此单字节的存放方法和传输方式一般相同。
对于多字节数据,如整数(32 位机器中一般占 4 字节),在不同的处理器的存放方式主要有两种,以内存中 0x0A0B0C0D 的存放方式为例,分别有以下几种方式:
大端序(big-endian)
将一个多位数的高位放在较小的地址处,低位放在较大的地址处(高位编址)。
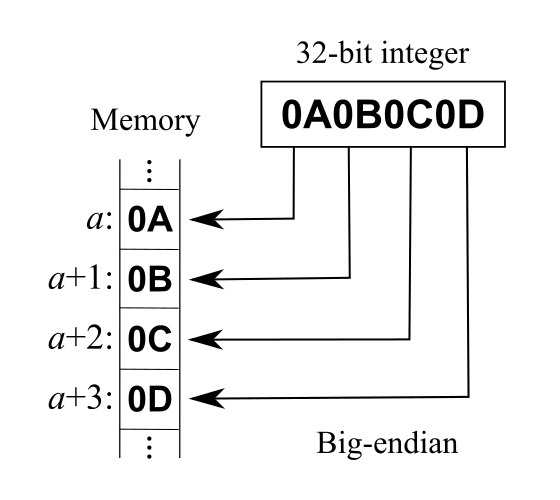
采用大端序的平台有 Motorola 6800、Motorola 68000、PowerPC 970、System/370、SPARC(除 V9 外)。网络传输一般采用大端序,也被称之为网络字节序,或网络序。IP 协议中定义大端序为网络字节序。
小端序(little-endian)
将一个多位数的低位放在较小的地址处,高位放在较大的地址处(低位编址)。
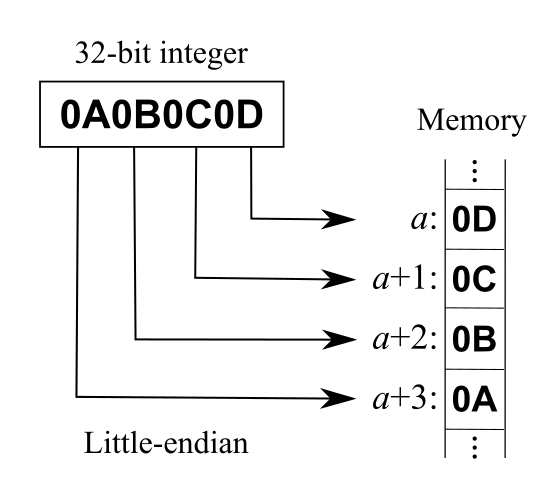
采用小端序的平台有 x86、MOS Technology 6502、Z80、VAX、PDP-11 等。
字节序转换
只有读写多字节的字才需要处理字节序,所以 u8、i8 和 bool 的读写无需处理,其他 u/i16、u/i32、u/i64 和 f32 的读写需要处理字节序。UTF8 字符串没有大小端之分,也不需要处理字节序。
对字的每个字节进行翻转的示意图如下:

对图中连线的字节进行位置调换。Rust 有对整型值提供了 swap_bytes 方法。如果希望自己实现,下面的实现可以高效地地完成这项工作:
pub fn swap_2_bytes(data: u16) -> u16 {
data >> 8 | data << 8
}
pub fn swap_4_bytes(data: u32) -> u32 {
data >> 24 & 0x0000_00FF |
data >> 8 & 0x0000_FF00 |
data << 8 & 0x00FF_0000 |
data << 24 & 0xFF00_0000
}
pub fn swap_8_bytes(data: u64) -> u64 {
data >> 56 & 0x0000_0000_0000_00FF |
data >> 40 & 0x0000_0000_0000_FF00 |
data >> 24 & 0x0000_0000_00FF_0000 |
data >> 8 & 0x0000_0000_FF00_0000 |
data << 8 & 0x0000_00FF_0000_0000 |
data << 24 & 0x0000_FF00_0000_0000 |
data << 40 & 0x00FF_0000_0000_0000 |
data << 56 & 0xFF00_0000_0000_0000
}
为了在 InputByteStream 和 OutputByteStream 中简化代码,我们只处理无符号 u16、u32、u64 的字节序,不在有符号整型的读写中处理字节序,对于有符号整数的读写,直接调用无符号整数的读写函数,因为他们的字节数是一样的,只是将相同的字节用在不同的表示(是否有符号)上。
为流添加一个 endianness 字段,用来表示流的字节序。修改 OutputByteStream 中的 write_u16、write_u32、write_u64 和 write_f32 函数:
pub fn write_u16(&mut self, data: u16) {
let mut data = data;
if self.endianness != get_platform_endianness() {
data = swap_2_bytes(data);
}
self.write(&data)
}
// `write_u32` 和 `write_u64` 基本和上述代码一致
pub fn write_f32(&mut self, data: f32) {
unsafe { self.write_u32(transmute(data)) }
}
修改 InputByteStream 中的 read_u16、read_u32、read_u64 和 read_f32 函数:
pub fn read_u16(&mut self) -> u16 {
let data = self.read_bytes(2);
if self.endianness != get_platform_endianness() {
swap_2_bytes(data)
} else {
data
}
}
// `read_u32` 和 `read_u64` 基本和上述代码一致
pub fn read_f32(&mut self) -> f32 {
unsafe { transmute(self.read_u32()) }
}
在读写整型值时,如果流的字节序与宿主机的字节序不一致,需要先进行字节序转换。但是浮点数有些不一样,由于 swap_bytes 使用位运算进行字节翻转,如果对浮点数直接进行位运算会得到错误的结果,所以 write_f32 是先把 f32 的 4 个字节表示为 u32,然后进行写入,read_f32 则是相反,读出 4 个字节 u32,再将这 4 个字节表示为 f32。
在这里,字节流的主要功能就实现了,整体下来,字节流是相对简单的,后面再来看看比特流。
比特流
字节流中数据的最小单位是 1 个字节,而比特流可以操作的最小数据单位是 1 比特。例如,布尔值可以只用 1 比特表示,也可以创造出 u4、u24 之类的原本没有的数据类型。
比特流的结构体和字节流差不多:
pub struct OutputBitStream {
pub buf: Vec<u8>,
pub bit_head: usize,
}
bit_head 表示比特的数据头位置,不再是之前的字节偏移。 在字节流一节中写入的数据 true、6E8 和 127,如果使用比特流实现,它的排列是:

与字节流不同的是,例如对于只占一比特的布尔值来说,只需要写入比特位数据,这使得一个字节内如果有剩余的比特位没有被使用,将会被写入下一份数据。
读写一(或者不足一)字节
编程语言的数据类型中最小的单位是 1 个字节,但是比特流允许写入小一个字节的数据,这说明我们需要处理多段数据在同一个字节内的情况。
读取一个字节是比特流中最重要的方法,因为实现它之后就隐藏了比特流和字节流的差异。
写入
write_byte 把小于等于 8 比特的数据写入缓冲区,并可以正确处理写入的数据跨缓冲区中的两个字节的情况。例如当前 bit_head 是 5,而即将写入新的 5 个比特,这时新的数据有一部分在第一个字节,另一部分在第二个字节,如图所示:

// 写入小于等于 8 位的数据
fn write_byte(&mut self, data: u8, bit_count: usize) {
...
// 计算字节偏移和位偏移
let byte_offset = self.byte_offset();
let bit_offset = self.bit_offset();
// 写入数据和原有数据进行组合
let current_mask = !(0xFF << bit_offset);
self.buf[byte_offset] = (self.buf[byte_offset] & current_mask) | (data << bit_offset);
let bits_free_this_byte = 8 - bit_offset;
// 将当前字节无法存下的剩余数据写入到下一个字节
if bits_free_this_byte < bit_count {
self.buf[byte_offset + 1] = data >> bits_free_this_byte;
}
self.bit_head = self.bit_head + bit_count;
}
通过 bit_count 参数指定写入的位数,可以写入少于一字节的数据,例如布尔值可以只写入一位。下面对上述的代码进行逐步分解。
写入数据时,需要知道当前流的字节偏移,以及位偏移量(代码中的 byte_offset 和 bit_offset),如下图的 bit_head 处于 10 的位置。

从图中很容易看出当前的字节偏移是 1,也就是正在第二个字节;位偏移是 2,也就是正在第二个字节的第 3 位。计算字节偏移和位偏移的伪代码是:
byte_offset = (bit_head / 8).floor();
bit_offset = bit_head % 8;
字节偏移等于 bit_head 除以 8 后取整,使用位运算的等价方式是右移 3 位;位偏移是对 8 取余,就是保留后面三个位,使用位运算的等价方式是 & 0x7(二进制编码中,最右边的三位取值范围就是 0-7);在源代码中对应着:
#[inline]
fn byte_offset(&self) -> usize { self.bit_head >> 3 }
#[inline]
fn bit_offset(&self) -> usize { self.bit_head & 0x7 }
知道字节偏移和位偏移后,就要写入数据了。假设现在一个字节已有 5 位数据 10001,再写入 3 位数据 101,那么这个字节的数据应该是 101_11000,也就是需要把低位的已有数据和高位的追加数据进行组合,这是通过或运算完成的:
原有的数据不变,高位为 0,追加的数据需要左移已有的比特数,用 0 填充,最后用或运算组合数据,即:
self.buf[byte_offset] = self.buf[byte_offset] | (data << bit_offset);
如果希望对缓冲区的历史数据进行覆盖,需要考虑原有数据高位默认不为 0 的情况,也就是上图左上角的三个数不为 0,这时需要对高位进行清零。对 ???_10001 执行此操作,可以使用 000_11111 & ???_10001 完成:
得到 00011111 的方式就是 !(0xFF < bit_offset),最终的组合代码是:
let current_mask = !(0xFF << bit_offset);
self.buf[byte_offset] = (self.buf[byte_offset] & current_mask) | (data << bit_offset);
如果连续写入两次 5 比特数据,最终会有 10 比特,这已经超过一个字节了,需要将剩余的 2 比特数据写入到下一个字节:
let bits_free_this_byte = 8 - bit_offset;
// 将当前字节无法存下的剩余数据写入到下一个字节
if bits_free_this_byte < bit_count {
self.buf[byte_offset + 1] = data >> bits_free_this_byte;
}
data >> bits_free_this_byte 会去掉当前字节已经写入的数据,将未写入部分写入到下个字节,例如上面的例如,需要写入的 5 个比特 10101,第一个字节剩余 3 个比特,那写完第一个字节会消耗掉右侧的 101,剩余未写入的数据就是右移三位后的 10。
最终将 bit_head 移动到新的位置。
读取
如果缓冲区的一个字节内有多段数据,写入时进行了数据组合,所以在读取数据时需要进行拆分。例如 10 比特数据 10101_10001,bit_head 位于索引 5,想要读取出第二段 5 个比特 10101,如图所示:
这段数据是分布在两个字节内的,所以需要分别在两个字节中读取出 10 和 101,然后组合成 10101。
使用右移分离出第一个字节中的部分数据,右移的位数是 bit_offset:
将上面得出的值与第二个字节进行计算:
左移第二个字节中的数据,位数是该字节内剩余的比特数,即 8 - bit_offset。与第一次计算得出的 101 进行或运算组合,这个时候得出的数据结尾已经是 10101 了,不过这个字节内可能还有其他数据,在上面的公式中用问号表示,为了清除这些位,让它与 00011111 进行与运算,它是通过 !(0xFF << bit_count) 得出。
代码形式是:
// 读取最多一个字节,允许读取 <= 8 数据。如果当前字节剩余位数不足,和下一个字节组合成一个 u8
fn read_byte(&mut self, bit_count: usize) -> u8 {
// 计算字节偏移和位偏移
let byte_offset = self.byte_offset();
let bit_offset = self.bit_offset();
// 左侧 8 - bit_offset 位数据
let mut out_data = self.buf[byte_offset] >> bit_offset;
let bits_free_this_byte = 8 - bit_offset;
if bits_free_this_byte < bit_count {
out_data |= self.buf[byte_offset + 1] << bits_free_this_byte;
}
out_data &= !(0xffu16 << bit_count) as u8;
self.bit_head += bit_count;
out_data
}
有了读写单字节数据的接口后,除了数据大小不是 8 的整数倍的情况,都可以像字节流那样使用比特流了。
读写多字节数据
有了写入一个字节的接口后,基于它可以再封装一个写入多字节数据的接口write_bytes。写入多字节数据只是重复地调用写入单字节数据接口。
fn write_bytes(&mut self, data: *const u8, bit_count: usize) {
let mut bit_count = bit_count;
let mut offset = 0;
while bit_count > 8 {
unsafe { self.write_byte(*data.offset(offset), 8); }
offset += 1;
bit_count -= 8;
}
if bit_count > 0 {
unsafe { self.write_byte(*data.offset(offset), bit_count); }
}
}
读取多个字节与写入相反,重复地调用读取单字节数据接口。
fn read_bytes(&mut self, byte_count: usize) -> Vec<u8> {
let mut bytes = vec![0u8; byte_count];
for i in 0..byte_count {
bytes[i] = self.read_byte(8);
}
bytes
}
读写任意数据
为了进一步简化最上层的接口,还可以提供一个中间层,用来写入任意数据,和字节流一节中的 write/read 作用一致。
fn write<T>(&mut self, obj: &T) {
self.write_bytes(
addr_of!(*obj) as *const u8,
size_of_val(obj) * 8,
);
}
...
fn read<T>(&mut self) -> T {
unsafe {
let bytes = self.read_bytes(size_of::<T>());
std::ptr::read(bytes.as_ptr() as *const _)
}
}
读写的数据大小通过 size_of_val 得到类型自身占用的字节数,转换为比特数,调用之前封装的 write_bytes 和 read_bytes 方法。现在有了 write 和 read,剩余的事情就简单多了。
读写基本数据类型
基于 write 方法,大部分数据的写入就变得非常简单,下面列出了写入 bool 和 u8 的接口,其他基本数据类型的写入与之类似,不再列出。
pub fn write_bool(&mut self, value: bool) {
self.write_byte(
if value { 1 } else { 0 },
1,
);
}
pub fn write_u8(&mut self, value: u8) { self.write(&value) }
pub fn write_i8(&mut self, value: i8) { self.write(&value) }
...
pub fn read_bool(&mut self) -> bool { self.read_byte(1) == 1 }
pub fn read_u8(&mut self) -> u8 { self.read() }
pub fn read_i8(&mut self) -> i8 { self.read() }
布尔值在内存中使用 u8 表示,所以为了写入一比特数据,write_bool 直接调用了 write_byte 接口,而其他基本数据全部是直接调用 write。
读写容器类数据
由于上面封装了一些底层接口,所以读写字符串和和字节流一致,不再赘述。
字节序
比特流也存在前面介绍的字节序问题。之前实现字节流时,我们通过判断平台字节序和目标字节序是否一致,如果不一致则交互字节。在 Rust 中,这能够更简单点,Rust 对整型类型提供了 to_le、to_be 和 to_ne 接口,分别是转成小端、转成大端和转成本地字节序,这里我们会用到前面两个。
为比特流添加 endianness 属性,表示流的字节序。为简化代码,多字节数据的读写被封装为宏,写入将调用 write_endianness,读取将调用 read_endianness。
修改以下接口的实现:
// OutputBitStream
pub fn write_u16(&mut self, value: u16) { write_endianness!(self, value) }
pub fn write_i16(&mut self, value: i16) { write_endianness!(self, value) }
pub fn write_u32(&mut self, value: u32) { write_endianness!(self, value) }
pub fn write_i32(&mut self, value: i32) { write_endianness!(self, value) }
pub fn write_u64(&mut self, value: u64) { write_endianness!(self, value) }
pub fn write_i64(&mut self, value: i64) { write_endianness!(self, value) }
pub fn write_f32(&mut self, value: f32) {
self.write_u32(unsafe { transmute(value) })
}
// InputBitStream
pub fn read_u16(&mut self) -> u16 { read_endianness!(self, u16) }
pub fn read_i16(&mut self) -> i16 { read_endianness!(self, i16) }
pub fn read_u32(&mut self) -> u32 { read_endianness!(self, u32) }
pub fn read_i32(&mut self) -> i32 { read_endianness!(self, i32) }
pub fn read_u64(&mut self) -> u64 { read_endianness!(self, u64) }
pub fn read_i64(&mut self) -> i64 { read_endianness!(self, i64) }
pub fn read_f32(&mut self) -> f32 {
unsafe { transmute(self.read_u32()) }
}
整型值直接调用宏方法。浮点数由于无法进行位运算,需要将它的内存数据表示为整型值进行读写。 write_endianness 宏和 read_endianness 宏分别在读写时处理了字节序:
macro_rules! write_endianness {
( $self: ident, $value: expr) => {{
if $self.endianness == Endianness::BigEndian {
$self.write(&$value.to_be())
} else {
$self.write(&$value.to_le())
}
}};
}
macro_rules! read_endianness {
( $self: ident, $t:ty ) => {{
const SIZE: usize = size_of::<$t>();
let bytes = $self.read_bytes(SIZE);
let ptr = bytes.as_ptr() as *const [u8; SIZE];
if $self.endianness == Endianness::BigEndian {
<$t>::from_be_bytes(unsafe { ptr.read() })
} else {
<$t>::from_le_bytes(unsafe { ptr.read() })
}
}};
}
下一步
本文介绍了如何实现字节流和比特流,在比特流中我们可以控制比特精度的数据。在使用比特流时,你需要确定一个字段取值的上限和下限,然后选择适当的数据类型,甚至于使用 u10 这种原本不存在的类型。这可能会让人感觉使用起来很麻烦,所以在编码阶段最好借助编程语言特性让编译器帮助我们完成尽可能多的工作,例如使用 Rust 中的 trait 和宏。
在文章的末尾,简单提一下 Protocol Buffers,Protocol Buffers 提供了 varints 类型,顾名思义,它是可变长度的整数表示,由于它的存在,整数类型能够以合适的长度进行编码,而不再是 u32 必然占用 4 个字节。在某些特殊情况下,它会比我们自己实现的流占用更多的空间,这个取舍在和使用成本、跨平台和其完善程度相比是值得的。Protocol Buffers 的官方网站有足够多的介绍,关于它的更多技术细节请参考官方文档。